
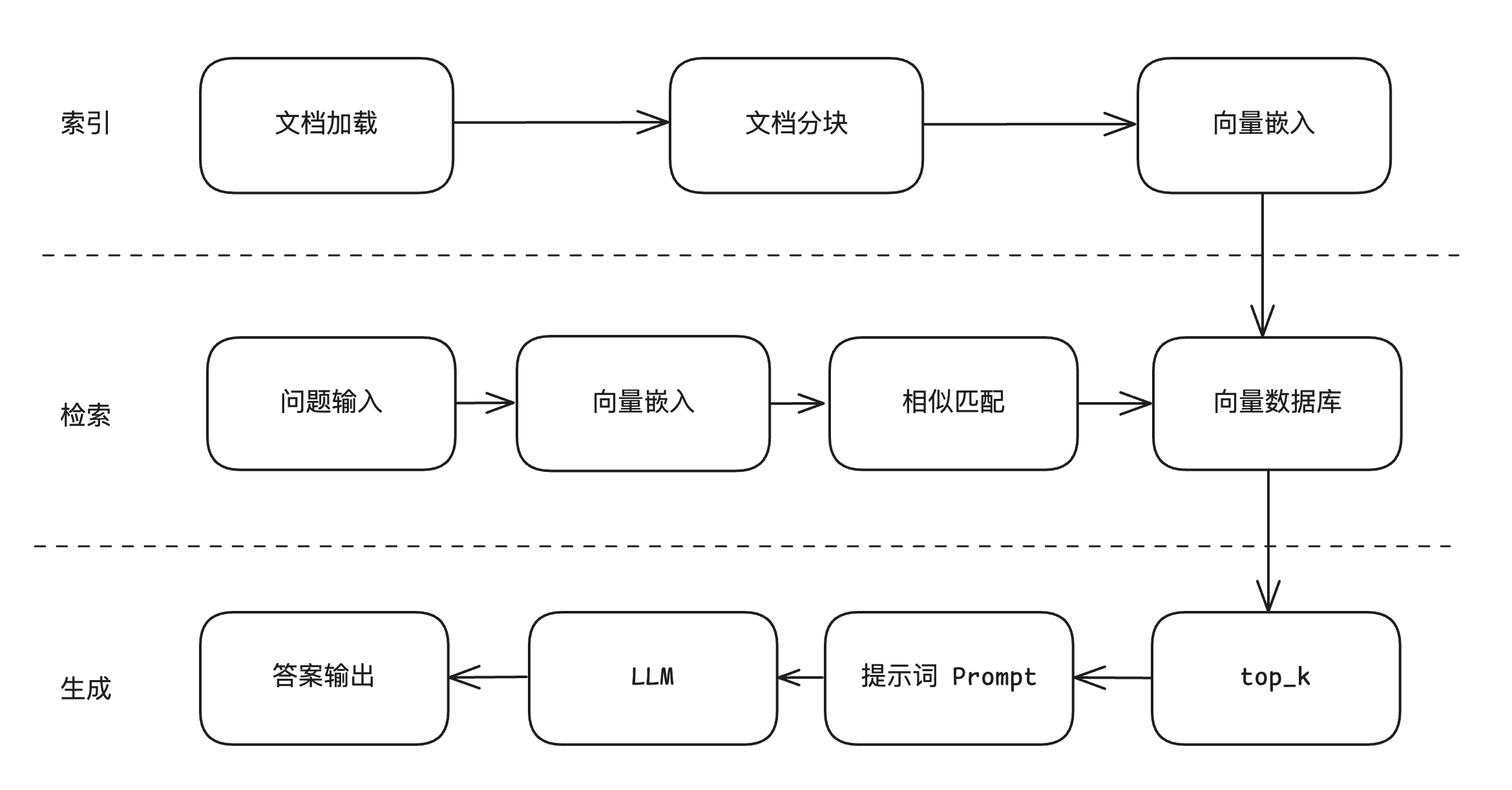
📖 阶段一:索引 (Indexing) —— “把书买回来,做好标签放进图书馆”
这个阶段是离线准备的,就像考试前你需要先整理好复习资料。
- 文档加载:你要查资料,首先得有书。这一步就是把你公司里的 PDF、Word、TXT、网页等各种格式的文档全部导进系统里。(进货买书)
- 文档分块:一整本书太厚了,大模型一口气读不完(受限于上下文窗口)。所以要把长文档切成一小段一小段的(Chunk)。比如按段落切,每段 500 字。(把书撕成一页页的“知识卡片”)
- 向量嵌入:计算机看不懂汉字,只懂数字。所以要用一个特殊的模型(Embedding 模型),把每一张“知识卡片”变成一串数学坐标(向量)。意思相近的句子,坐标就离得近。(给每张卡片打上“数学条形码”,按语义分类)
- 图中的箭头向下:这些打了条形码的卡片,最终都被存进了下一层楼的向量数据库中,随时备查。
🔍 阶段二:检索 (Retrieval) —— “遇到考试题,去图书馆找相关的书页”
这个阶段是实时发生的,用户开始提问了。
- 问题输入:用户问了一个问题,比如:“公司的报销流程是什么?”(看到考试卷上的题目)
- 向量嵌入:为了能在图书馆里找到答案,必须把用户的“问题”也变成同样的数学坐标(向量)。(把考试题目也翻译成“数学条形码”)
- 相似匹配 向量数据库:拿着问题的条形码,去向量数据库里扫一圈,计算数学距离(比如余弦相似度)。距离越近,说明卡片上的内容跟问题越相关。(图书管理员拿着你的题目,去书架上比对,找出最相关的卡片)
✍️ 阶段三:生成 (Generation) —— “照着找出来的资料,组织语言写出答案”
资料找到了,现在要让大模型开始写作业了。
- top_k:数据库里可能匹配出成百上千相关的段落,但我们只要最相关的前几个(K一般设为3或5)。(挑出最最相关的 3 张知识卡片放在桌上)
- 提示词 Prompt:这是最关键的“拼接”环节。系统会在后台把“用户的原始问题”和“找出来的 top_k 知识卡片”缝合在一起,形成一段固定格式的话。
- (画外音提示词类似于:“LLM你好,请根据以下参考资料【卡片1、卡片2、卡片3】,回答用户的问题【报销流程是什么?】”)
- LLM:大语言模型(像 ChatGPT)接收到了上面拼好的 Prompt。这时候,它不仅知道问题是什么,而且手边就有了正确答案的参考资料。(学生看着考卷题目,同时照着桌上的复习卡片开始作答)
- 答案输出:LLM 消化了参考资料的内容,用自然人类语言润色后输出给用户。完美避免了幻觉!(交出满分答卷)
🧠 一句话记忆口诀:
为了加深记忆,你可以用这句顺口溜记住整张图:
“切碎资料变向量(索引),问题比对找前K(检索),拼进Prompt喂模型(生成)。”