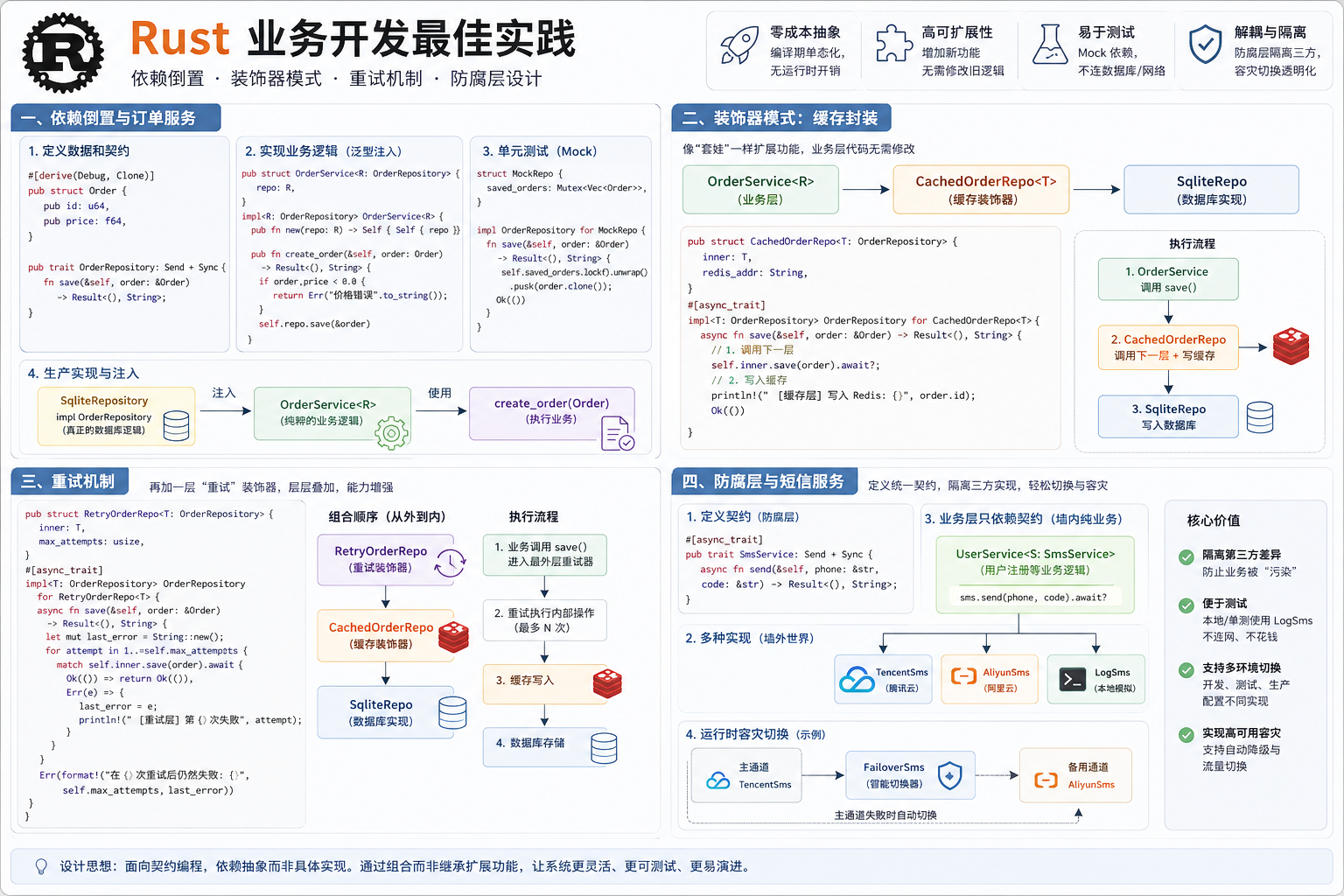
在 Rust 中实现”依赖倒置”(Dependency Inversion)非常自然。Rust 使用
Trait 来定义契约,并利用
泛型(Generics) 或
Trait 对象(Trait Objects) 来注入依赖。
一、依赖倒置与订单服务
1.1 定义数据和契约
首先定义业务对象和它需要的操作接口。
1
2
3
4
5
6
7
8
9
10
| #[derive(Debug, Clone)]
pub struct Order {
pub id: u64,
pub price: f64,
}
pub trait OrderRepository: Send + Sync {
fn save(&self, order: &Order) -> Result<(), String>;
}
|
1.2 实现业务逻辑
在 Rust 中,我们通常使用泛型来实现这种注入。这在编译时就会确定类型,性能极高。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
pub struct OrderService<R: OrderRepository> {
repo: R,
}
impl<R: OrderRepository> OrderService<R> {
pub fn new(repo: R) -> Self {
Self { repo }
}
pub fn create_order(&self, order: Order) -> Result<(), String> {
if order.price < 0.0 {
return Err("价格错误".to_string());
}
self.repo.save(&order)
}
}
|
1.3 单元测试
有了抽象,测试业务逻辑就变得非常简单,不需要启动任何数据库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| #[cfg(test)]
mod tests {
use super::*;
use std::sync::Mutex;
struct MockRepo {
saved_orders: Mutex<Vec<Order>>,
}
impl OrderRepository for MockRepo {
fn save(&self, order: &Order) -> Result<(), String> {
let mut orders = self.saved_orders.lock().unwrap();
orders.push(order.clone());
Ok(())
}
}
#[test]
fn test_create_order_logic() {
let mock_repo = MockRepo { saved_orders: Mutex::new(vec![]) };
let service = OrderService::new(mock_repo);
let bad_order = Order { id: 1, price: -10.0 };
assert!(service.create_order(bad_order).is_err());
let good_order = Order { id: 2, price: 100.0 };
assert!(service.create_order(good_order).is_ok());
}
}
|
1.4 生产环境的真实实现
在生产代码中,你才去实现真正的数据库逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| struct SqliteRepository {
}
impl OrderRepository for SqliteRepository {
fn save(&self, order: &Order) -> Result<(), String> {
println!("正在将订单 {} 写入 SQLite 数据库...", order.id);
Ok(())
}
}
fn main() {
let repo = SqliteRepository {};
let service = OrderService::new(repo);
let _ = service.create_order(Order { id: 101, price: 50.0 });
}
|
二、装饰器模式:缓存封装
我们延续之前的例子,展示如何在不改动 OrderService 的情况下,像”套娃”一样把 Redis 功能套上去。
2.1 定义核心契约
1
2
3
4
5
6
7
8
9
| use async_trait::async_trait;
#[derive(Debug, Clone)]
pub struct Order { pub id: u64, pub price: f64 }
#[async_trait]
pub trait OrderRepository: Send + Sync {
async fn save(&self, order: &Order) -> Result<(), String>;
}
|
2.2 数据库实现
1
2
3
4
5
6
7
8
9
| pub struct SqliteRepo;
#[async_trait]
impl OrderRepository for SqliteRepo {
async fn save(&self, order: &Order) -> Result<(), String> {
println!(" [DB层] 正在将订单 {} 存入 Sqlite...", order.id);
Ok(())
}
}
|
2.3 缓存装饰器
重点: 它也实现 OrderRepository,但它内部持有另一个实现了该 Trait 的类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| pub struct CachedOrderRepo<T: OrderRepository> {
inner: T,
redis_addr: String,
}
impl<T: OrderRepository> CachedOrderRepo<T> {
pub fn new(inner: T, addr: &str) -> Self {
Self { inner, redis_addr: addr.to_string() }
}
}
#[async_trait]
impl<T: OrderRepository> OrderRepository for CachedOrderRepo<T> {
async fn save(&self, order: &Order) -> Result<(), String> {
self.inner.save(order).await?;
println!(" [缓存层] 正在将订单 {} 写入 Redis ({})", order.id, self.redis_addr);
Ok(())
}
}
|
2.4 业务逻辑层——保持不变
注意: 这里的代码和加缓存之前完全一模一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| pub struct OrderService<R: OrderRepository> {
repo: R,
}
impl<R: OrderRepository> OrderService<R> {
pub fn new(repo: R) -> Self { Self { repo } }
pub async fn create_order(&self, order: Order) -> Result<(), String> {
if order.price < 0.0 { return Err("价格错误".to_string()); }
self.repo.save(&order).await
}
}
|
2.5 程序入口处组装
这是见证奇迹的时刻:你通过改变对象的组合方式,改变了系统的行为,而没有修改业务逻辑代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #[tokio::main]
async fn main() {
let sqlite_repo = SqliteRepo;
let cached_repo = CachedOrderRepo::new(sqlite_repo, "redis://127.0.0.1");
let service = OrderService::new(cached_repo);
let my_order = Order { id: 888, price: 99.0 };
service.create_order(my_order).await.unwrap();
}
|
2.6 这种写法的优势
零成本抽象 (Zero-cost Abstraction):
如果你使用泛型,Rust 编译器在编译时会进行”单态化”(Monomorphization)。它会直接生成一套专门调用 Sqlite 后接 Redis 的机器码。没有运行时的虚函数表查找开销,性能等同于你手写的硬编码代码。
职责单一 (SRP):
OrderService: 只管业务逻辑(价格对不对)。SqliteRepo: 只管 SQL 怎么写。CachedOrderRepo: 只管 Redis 怎么存。
如果你下周要加 Kafka,你只需要再写一个 KafkaOrderRepo 并在 main 函数里再套一层。
极度好写测试:
- 你想测
OrderService?给它塞一个 MockRepo(不连 DB,不连 Redis)。
- 你想测
CachedOrderRepo 的缓存逻辑?给它塞一个 MockRepo 作为 inner。
符合开闭原则 (OCP):
软件实体应对扩展开放,对修改关闭。你通过增加新类实现了新功能,而不是通过修改旧代码实现新功能。
三、重试机制
这就是装饰器模式最迷人的地方。我们可以非常轻松地再加一层”重试”逻辑,而无需触碰现有的 OrderService、SqliteRepo 或 CachedOrderRepo 的任何代码。
3.1 RetryOrderRepo 实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| pub struct RetryOrderRepo<T: OrderRepository> {
inner: T,
max_attempts: usize,
}
impl<T: OrderRepository> RetryOrderRepo<T> {
pub fn new(inner: T, max_attempts: usize) -> Self {
Self { inner, max_attempts }
}
}
#[async_trait]
impl<T: OrderRepository> OrderRepository for RetryOrderRepo<T> {
async fn save(&self, order: &Order) -> Result<(), String> {
let mut last_error = String::new();
for attempt in 1..=self.max_attempts {
println!(" [重试层] 正在进行第 {} 次尝试...", attempt);
match self.inner.save(order).await {
Ok(()) => return Ok(()),
Err(e) => {
last_error = e;
println!(" [重试层] 第 {} 次尝试失败: {}", attempt, last_error);
}
}
}
Err(format!("在 {} 次重试后仍然失败: {}", self.max_attempts, last_error))
}
}
|
3.2 套娃组装
现在的组装顺序是:
Service -> Retry (重试) -> Cache (缓存) -> Sqlite (数据库)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #[tokio::main]
async fn main() {
let sqlite_repo = SqliteRepo;
let cached_repo = CachedOrderRepo::new(sqlite_repo, "redis://127.0.0.1");
let retry_repo = RetryOrderRepo::new(cached_repo, 3);
let service = OrderService::new(retry_repo);
let my_order = Order { id: 999, price: 150.0 };
if let Err(e) = service.create_order(my_order).await {
println!("最终执行失败: {}", e);
} else {
println!("最终执行成功!");
}
}
|
3.3 套娃顺序的讲究
Retry 包裹 Cache (Retry(Cache(DB))):
- 语义:如果”写DB+写缓存”整体失败了,就重试整个过程。
- 适用场景:你希望保证缓存和数据库最终一致。
Cache 包裹 Retry (Cache(Retry(DB))):
- 语义:重试只针对 DB 写入。只有 DB 真的写成功了,才去写一次缓存。
- 适用场景:你认为缓存写入通常不会失败,只有 DB 写入需要重试。
Logging 包裹一切 (Log(Retry(Cache(DB)))):
四、防腐层与短信服务
这个例子展示了架构设计中极其重要的 “防腐层”(Anti-Corruption Layer, ACL) 概念。
4.1 定义短信契约与业务层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| use async_trait::async_trait;
#[async_trait]
pub trait SmsService: Send + Sync {
async fn send(&self, phone: &str, code: &str) -> Result<(), String>;
}
pub struct UserService<S: SmsService> {
sms: S,
}
impl<S: SmsService> UserService<S> {
pub fn new(sms: S) -> Self { Self { sms } }
pub async fn register(&self, phone: &str) -> Result<(), String> {
println!("[业务逻辑] 开始注册用户: {}", phone);
let code = "123456";
self.sms.send(phone, code).await?;
println!("[业务逻辑] 注册成功!");
Ok(())
}
}
|
4.2 多种发送方式实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
pub struct TencentSms { api_key: String }
#[async_trait]
impl SmsService for TencentSms {
async fn send(&self, phone: &str, code: &str) -> Result<(), String> {
println!(" [腾讯云] 调用 SDK 发送短信至 {},验证码:{}", phone, code);
Ok(())
}
}
pub struct AliyunSms { secret_id: String }
#[async_trait]
impl SmsService for AliyunSms {
async fn send(&self, phone: &str, code: &str) -> Result<(), String> {
println!(" [阿里云] 调用 SDK 发送短信至 {},验证码:{}", phone, code);
Ok(())
}
}
pub struct LogSms;
#[async_trait]
impl SmsService for LogSms {
async fn send(&self, phone: &str, code: &str) -> Result<(), String> {
println!(" [本地模拟] 模拟发送短信至 {},验证码:{}", phone, code);
Ok(())
}
}
|
4.3 不同场景的组装
1
2
3
4
5
6
7
8
9
10
11
12
| #[tokio::main]
async fn main() {
let dev_service = UserService::new(LogSms);
dev_service.register("13800138000").await.unwrap();
let prod_sms = TencentSms { api_key: "TX_123".to_string() };
let prod_service = UserService::new(prod_sms);
prod_service.register("13911112222").await.unwrap();
}
|
4.4 深度价值
4.4.1 彻底解决”测试地狱”
如果没有这个 Trait,你写单元测试时必须处理腾讯云 SDK 的初始化、网络连接等。
有了 Trait,你在测试文件里写一个 struct TestSms,在 send 方法里直接 return Ok(())。你的测试运行速度会从秒级降至毫秒级,且不消耗任何短信资费。
4.4.2 实现防腐层 (Anti-Corruption)
腾讯云 SDK 的 API 设计可能很古怪。如果你直接在 UserService 里用,你的业务逻辑就被腾讯的 API 风格”污染”了。
- Trait 就像一堵墙:墙内是纯粹的业务语言(
phone, code),墙外是肮脏的第三方 SDK 细节。
- 更换供应商:换阿里云时,你只需要写一个新的
AliyunSms 实现类,业务代码一行都不用动。
4.5 运行时容灾切换
你可以利用 Rust 的 dyn SmsService 实现一个”智能切换器”:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| pub struct FailoverSms {
primary: TencentSms,
secondary: AliyunSms,
}
#[async_trait]
impl SmsService for FailoverSms {
async fn send(&self, phone: &str, code: &str) -> Result<(), String> {
match self.primary.send(phone, code).await {
Ok(_) => Ok(()),
Err(_) => {
println!("!!! 腾讯云异常,正在切换到阿里云备用通道...");
self.secondary.send(phone, code).await
}
}
}
}
|
这种强大的容灾能力,对于业务层 UserService 来说是完全透明的! 业务层只管调 send,它根本不知道背后发生了惊心动魄的线路切换。